ComfyUI新手教程:入门指南
引言
欢迎来到ComfyUI的世界!ComfyUI是一个强大的图形界面工具,专为与深度学习模型协同工作而设计。在这个教程中,我们将引导你逐步了解ComfyUI的基础知识,并帮助你开始构建自己的创意工作流。在我们开始之前,让我们先探讨为什么你应该学习ComfyUI。
为什么选择ComfyUI?
市场上存在着各种类型的产品,它们大致可以分为两类:
- 融合型产品:如Midjourney、Stability AI等,它们将模型与产品紧密集成。
- 分离型产品:如SD Web UI和ComfyUI,它们允许模型与用户界面分离。
以下两类产品的优缺点对比:
| 特性 |
融合型产品 |
分离型产品 |
| 学习成本 |
低,用户体验优化,提供教程。 |
高,开源性质,开发者众多,可能缺乏优化和教程。 |
| 迁移成本 |
高,需重新学习产品及模型知识。 |
低,只需学习模型知识。 |
| 自由度 |
低,封闭系统,功能有限。 |
高,开源,可自由修改和开发。 |
| 费用 |
高,通常需要付费使用。 |
中,提供本地版本,可自备GPU,无需额外费用。 |
选择哪种产品取决于你的需求。如果你只是寻求娱乐,偶尔制作图片或视频,融合型产品可能是更好的选择。但如果你是专业人士,希望利用AI技术创造价值,分离型产品将为你提供更大的灵活性和控制权。
学习ComfyUI的优势
- 迁移成本低:随着AI行业的快速发展,学会使用ComfyUI等分离型产品,可以让你轻松适应新的模型和技术,无需重新学习整个软件。
- 高度自由度:ComfyUI允许你调整和优化AI模型,以适应你的工作流程,甚至可以开发新的功能。
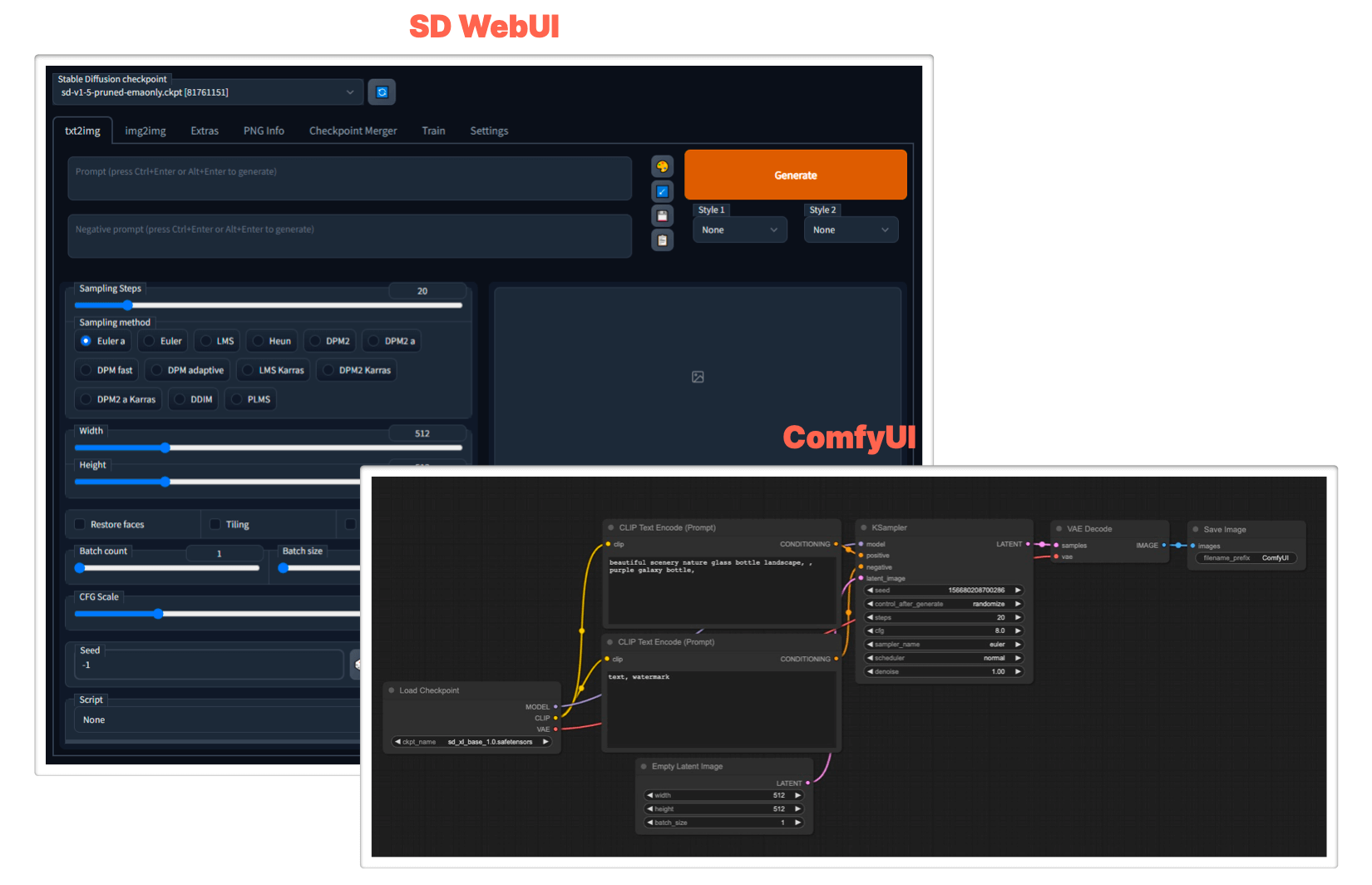
SD Web UI与ComfyUI对比
为什么在众多分离型产品中选择ComfyUI?
开始使用ComfyUI
在本教程中,我们将涵盖以下内容:
- 安装和设置:如何正确安装和配置ComfyUI环境。
- 基础操作:了解ComfyUI界面,学习如何添加和连接节点。
- 构建第一个工作流:通过一个简单的例子,学习如何构建一个基本的工作流。
- 进阶技巧:探索如何自定义节点和优化工作流。
准备好了吗?让我们开始你的ComfyUI之旅吧!
开始入门
以下是安装 ComfyUI 的大概步骤:
本地安装方法
命令行安装
安装 pytorch:
- Windows 用户:使用 Miniconda3 安装 pytorch 的 nightly 版本。
- Mac 用户:根据芯片类型下载 Miniconda3,然后安装 pytorch 的 nightly 版本。
下载 ComfyUI:
- 使用 Git 命令
git clone https://github.com/comfyanonymous/ComfyUI。
- 或者使用 GitHub Desktop 客户端下载。
安装依赖:
- 在 VS Code 中打开项目文件夹,在终端运行
pip install -r requirements.txt。
- 或者直接在 Terminal 中 cd 到项目文件夹,然后运行
pip install -r requirements.txt。
启动服务:
- 在项目文件夹的终端中运行
python main.py。
安装包安装
官方安装包:仅支持 Windows 系统,显卡必须是 Nivida。下载地址:ComfyUI 官方安装包。
Jupyter Notebook:要在paperspace、kaggle 或 colab 等服务上运行,可以使用 Jupyter脚本。
Mac/Linux:mac和linux环境,请移步官方的安装指南
Q&A
- 模块下载失败:配置终端代理。
- pyyaml 错误:运行
pip install pyyaml。
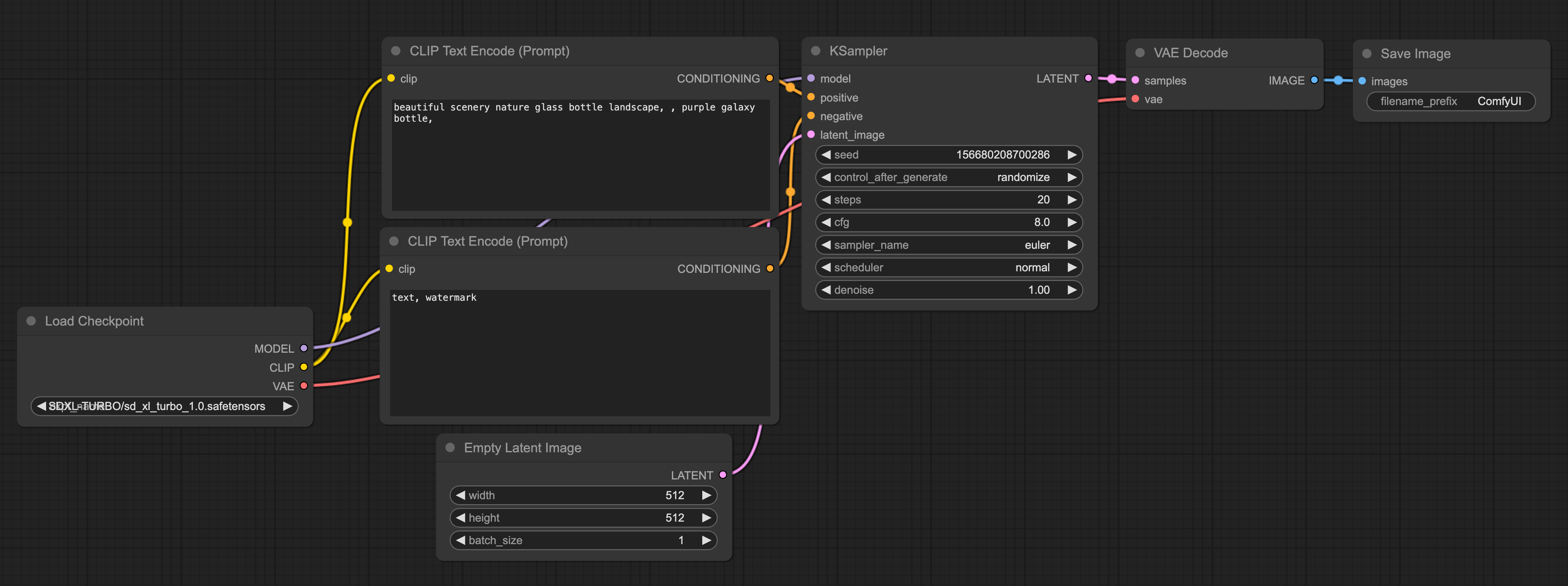
完成安装后,打开浏览器输入 http://127.0.0.1:8188/ 即可访问 ComfyUI。默认界面如下图,
参考
下载 & 导入模型
安装完 ComfyUI 后,你需要下载对应的模型,并将模型导入到 ComfyUI 的 models 目录下。以下是详细步骤:
不同 Stable Diffusion 版本
- Stable Diffusion v1.5:早期版本,许多 Lora 和 ContrlNet 模型基于它构建。下载地址
- Stable Diffusion v2.0:重大更新,图像质量和速度提升,采用新的文本编码器 OpenCLIP。release
- Stable Diffusion XL:最新版本,模型大小更大,生成更高质量的图像。下载地址
模型下载
- HuggingFace:搜索并下载模型,推荐下载 safetensors 格式的模型。
- CivitAI:搜索并下载模型,提供更多个人训练的模型。
模型导入
- 未安装过 SD WebUI:下载模型后,将其放入 ComfyUI 的 models 目录下对应的文件夹。
- 已安装 SD WebUI:修改 ComfyUI 中的
extra_model_paths.yaml.example 文件,将其改为 extra_model_paths.yaml,并配置 SD WebUI 的路径。
完成模型导入后,ComfyUI 就可以加载并使用这些模型了。
核心节点介绍
高级节点
Diffusers Loader
Diffusers Loader节点可以用于加载来自diffusers的扩散模型。
输入:model_path(指向diffusers模型的路径。)
输出:MODEL(用于对潜在变量进行降噪的模型)CLIP(用于对文本提示进行编码的CLIP模型。)
VAE(用于将图像编码至潜在空间,并从潜在空间解码图像的VAE模型。)
Load Checkpoin(with config)【加载Checkpoint(带配置)节点】
“加载检查点(带配置)”节点可以根据提供的配置文件加载扩散模型。请注意,常规的加载检查点节点在大部分情况下能够推测出适当的配置。
输入:config_name(配置文件的名称)、ckpt_name(要加载的模型的名称);
输出:MODEL(用于去噪潜在变量的模型)、CLIP(用于编码文本提示的CLIP模型)、VAE(用于将图像编码和解码到潜在空间的VAE模型。)
VAE 解码(tiled)节点
VAE 解码(瓦片式)节点可用于将潜在空间图像解码回像素空间图像,使用提供的 VAE(变分自编码器)。该节点以瓦片的方式解码潜在图像,使其能够解码比常规 VAE 解码节点更大的潜在图像。
信息:当常规 VAE 解码节点由于 VRAM(视频随机存取存储器)不足而失败时,comfy(一种软件)将自动使用瓦片式实现进行重试。
输入参数为待解码的潜在图像和用于解码潜在图像的 VAE。输出结果是解码后的图像。
VAE 编码(tiled)节点
VAE 编码(瓦片式)节点可用于将像素空间图像编码为潜在空间图像,使用提供的 VAE(变分自编码器)。该节点以瓦片的方式编码图像,使其能够编码比常规 VAE 编码节点更大的图像。
信息:当常规 VAE 编码节点由于 VRAM(视频随机存取存储器)不足而失败时,comfy将自动使用瓦片式实现进行重试。
输入参数为待编码的像素空间图像和用于编码像素图像的 VAE。输出结果是编码后的潜在图像。
Conditioning(条件设定节点)
在 ComfyUI 中,Conditioning(条件设定)被用来引导扩散模型生成特定的输出。所有的Conditioning(条件设定)都开始于一个由 CLIP 进行嵌入编码的文本提示,这个过程使用了 Clip Text Encode 节点。这些条件可以通过本段中找到的其他节点进行进一步增强或修改。
例如,使用 Conditioning (Set Area)、Conditioning (Set Mask) 或 GLIGEN Textbox Apply 节点,可以引导过程朝着某种组合进行。
或者,通过 Apply Style Model、Apply ControlNet 或 unCLIP Conditioning 节点等,提供额外的视觉提示。相关节点的完整列表可以在侧边栏中找到。
Apply ControlNet(应用 ControlNet 节点)
Apply ControlNet 节点能够为扩散模型提供更深层次的视觉引导。不同于 unCLIP 嵌入,controlnets 和 T2I 适配器能在任何模型上工作。通过联接多个节点,我们可以使用多个 controlNets 或 T2I 适配器来引导扩散模型。例如,通过提供一个包含边缘检测的图像和一个在边缘检测图像上训练的 controlNet,我们可以向扩散模型提示在最终图像中的边缘应该在哪里。
输入:包括conditioning(一个conditioning)、control_net(一个已经训练过的controlNet或T2IAdaptor,用来使用特定的图像数据来引导扩散模型)、image(用作扩散模型视觉引导的图像)。
输出:CONDITIONING,这是一个包含 control_net 和视觉引导的 Conditioning。
应用样式模型节点(Apply Style Model node)
应用风格模型节点可用于为扩散模型(diffusion model)提供进一步的视觉指导,特别是关于生成图像的风格。该节点接收一个T2I风格适配器(style adaptor)模型和一个CLIP视觉模型(CLIP vision model)的嵌入(embedding),以引导扩散模型朝向CLIP视觉模型嵌入的图像风格发展。
输入:包括条件(conditioning)、T2I风格适配器(style_model)、以及一个由CLIP视觉模型编码的包含期望风格的图像(CLIP_vision_output)。条件是一个特定的条件。T2I风格适配器是一个特定的模型,而CLIP视觉模型的输出是一个包含期望风格的图像。
输出:是一个包含T2I风格适配器和对期望风格的视觉指导的条件(CONDITIONING)。
CLIP 设置最后一层节点 (CLIP Set Last Layer Node)
CLIP 设置最后一层节点 (CLIP Set Last Layer node) [1]用于设置从哪个 CLIP 输出层获取文本嵌入。文本被编码成嵌入的过程是通过 CLIP 模型的多层变换实现的。虽然传统的扩散模型通常根据 CLIP 的最后一层的输出进行条件设定,但有些扩散模型是基于早期层的条件设定的,如果使用最后一层的输出,可能效果不佳。
这个节点的输入 (inputs) 是用于编码文本的 CLIP 模型。输出 (outputs) 则是设置了新的输出层的 CLIP 模型。这样,我们可以根据需要,控制从哪一层获取文本嵌入,以适应不同的扩散模型条件。
CLIP 文本编码 (Prompt) 节点 (CLIP Text Encode (Prompt) Node)
CLIP 文本编码 (Prompt) 节点可以使用 CLIP 模型将文本提示编码成嵌入,这个嵌入可以用来指导扩散模型生成特定的图片。关于 ComfyUI 中所有文本提示相关特性的完整指南,请参阅Text Prompts页面。
这个节点需要输入一个 CLIP 模型和一个需要被编码的文本。CLIP 模型用于将输入的文本转化为嵌入,而输入的文本则是你希望模型理解并生成相关图片的内容。经过这个节点处理后,你将得到一个包含嵌入文本的条件(Conditioning),这个条件用于指导扩散模型生成图片。
CLIP 视觉编码节点 (CLIP Vision Encode Node)
CLIP 视觉编码节点用于使用 CLIP 视觉模型将图片编码成嵌入,这个嵌入可以用来指导 unCLIP 扩散模型,或者作为样式模型的输入。
这个节点的输入包括一个用于编码图片的 CLIP 视觉模型和一个需要被编码的图片。CLIP 视觉模型的任务就是将输入的图片转化为嵌入,而输入的图片则是你希望模型理解并进行处理的图像。经过这个节点处理后,将输出编码后的图片。
平均调节 (Conditioning (Average)) 节点
平均调节节点可以根据在 conditioning_to_strength 中设置的强度因子,将两个文本嵌入值进行插值处理。
输入:参数包括 conditioning_to、conditioning_from 和 conditioning_to_strength。其中 conditioning_to 是在 conditioning_to_strength 为1时的调节文本嵌入值,conditioning_from 则是在 conditioning_to_strength 为0时的调节文本嵌入值。conditioning_to_strength 是用于控制将 conditioning_to 混入 conditioning_from 的混合因子。[2]
输出: CONDITIONING,这是一个新的调节文本嵌入值,它根据 conditioning_to_strength 的设定混合了输入的文本嵌入值。
调节(合并)节点
调节(合并)节点(Conditioning (Combine) node)可以通过平均扩散模型的预测噪声来合并多个调节。注意,这与调节(平均)节点(Conditioning (Average) node)是不同的。在这里,对不同调节的扩散模型输出(即构成调节的所有部分)进行平均,而调节(平均)节点则是在调节内部存储的文本嵌入之间进行插值。
输入包括第一个调节(conditioning_1)和第二个调节(conditioning_2)。输出为一个包含两个输入的新调节(CONDITIONING),稍后将由采样器进行平均。
调节(设置区域)节点
调节(设置区域)节点(Conditioning (Set Area) node)可以用来将调节限制在图像的指定区域内。结合调节(合并)节点(Conditioning (Combine) node),可以增加对最终图像构成的控制。
输入包括将被限制到一个区域的调节(conditioning),区域的宽度(width)、高度(height)、x坐标(x)、y坐标(y),以及在混合多个重叠调节时,要使用的区域的权重(strength)。输出为限制在指定区域的新调节(CONDITIONING)。
调节(设置遮罩)节点
调节(设置遮罩)节点(Conditioning (Set Mask) node)可以用来将调节限制在指定的遮罩内。结合调节(合并)节点(Conditioning (Combine) node),可以增加对最终图像构成的控制。
输入包括将被限制到遮罩的调节(conditioning),约束调节的遮罩(mask),以及在混合多个重叠调节时,要使用的遮罩区域的权重(strength)。还可以设置是否对整个区域进行去噪,或将其限制在遮罩的边界框内(set_cond_area)。输出为限制在指定遮罩内的新调节(CONDITIONING)。
GLIGEN文本框应用节点
GLIGEN文本框应用节点(GLIGEN Textbox Apply node)可以用于为扩散模型提供更进一步的空间指导,引导它在图像的特定区域生成指定的提示部分。虽然文本输入会接受任何文本,但如果输入的是文本提示的一部分对象,GLIGEN的效果最好。
输入包括一个调节(conditioning_to)、一个CLIP模型(clip)、一个GLIGEN模型(gligen_textbox_model)、要关联空间信息的文本(text)、区域的宽度(width)、高度(height)、x坐标(x)和y坐标(y)。输出为包含GLIGEN和空间指导的调节(CONDITIONING)。
unCLIP条件化节点 (unCLIP Conditioning node)
unCLIP条件化节点 (unCLIP Conditioning node) 能够为unCLIP模型提供额外的视觉引导,通过由CLIP视觉模型编码的图像。这个节点可以串联起来,提供多张图像作为引导。
输入参数包括条件化 (conditioning)、由CLIP视觉模型编码的图像 (clip_vision_output)、unCLIP扩散模型应该受到图像多大的引导 (strength) 以及噪声增强 (noise_augmentation)。噪声增强可以用于引导unCLIP扩散模型随机地在原始CLIP视觉嵌入的邻域里移动,提供与编码图像密切相关的生成图像的额外变化。输出则是一种包含了unCLIP模型额外视觉引导的条件化 (CONDITIONING)。
Image(图像)
ComfyUI 提供了各种节点来操作像素图像。这些节点可以用于加载 img2img(图像到图像)工作流程的图像,保存结果,或者例如,为高分辨率工作流程放大图像。
图像反转节点(Invert Image)
图像反转节点可以用来反转图像的颜色。
输入参数为待反转的像素图像。输出结果是反转后的像素图像。
加载图像节点
加载图像节点可用于加载图像。可以通过启动文件对话框或将图像拖放到节点上来上传图像。一旦图像被上传,它们可以在节点内部被选择。
信息:默认情况下,图像将被上传到 ComfyUI 的输入文件夹。
输入参数为待使用的图像名称。输出结果是像素图像和图像的 alpha 通道。
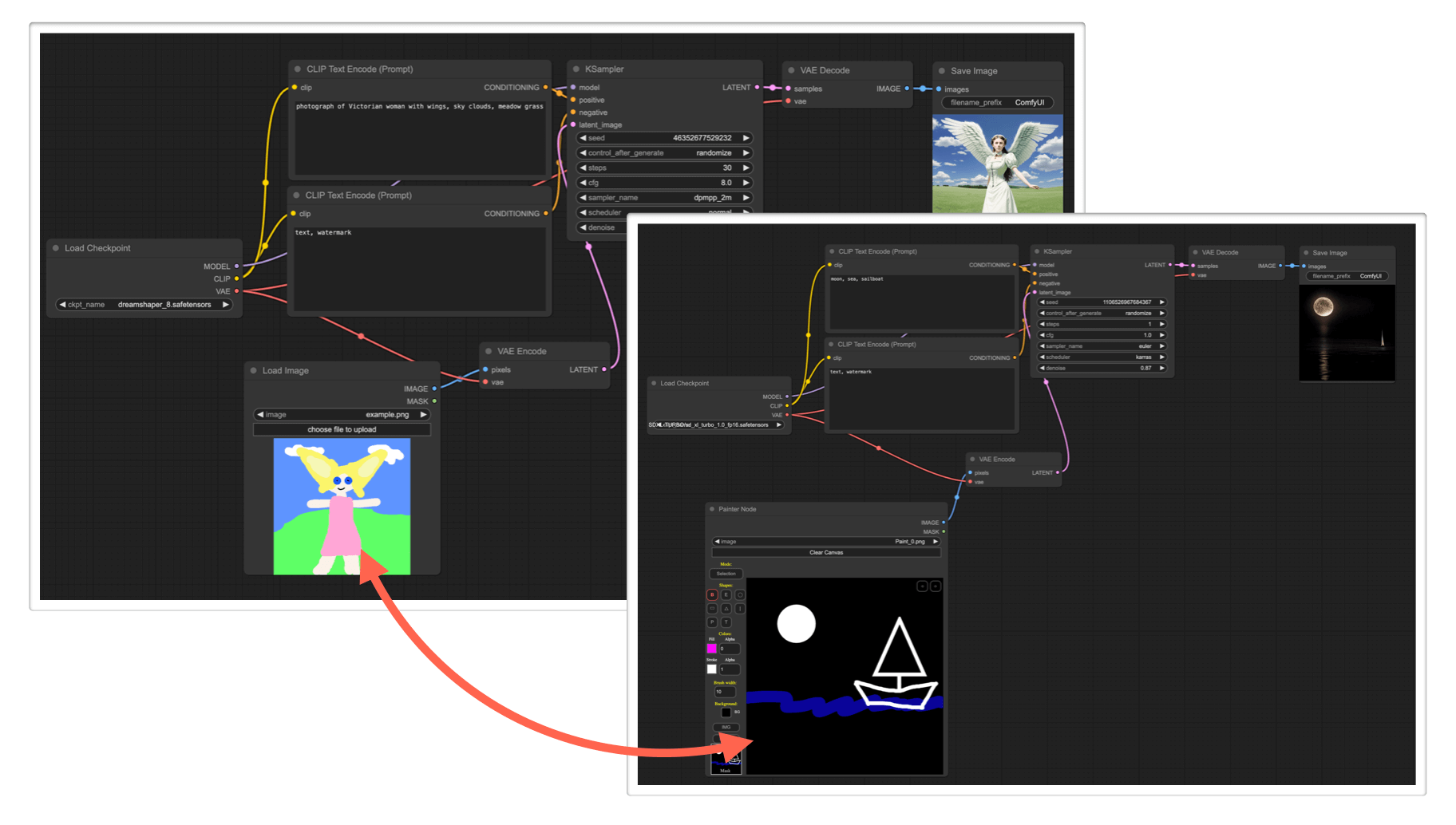
示例:为了执行图像到图像的生成,你需要使用加载图像节点来加载图像。在下面的例子中,一个图像是使用加载图像节点加载的,然后被一个 VAE 编码节点编码到潜在空间,让我们能够执行图像到图像的任务。
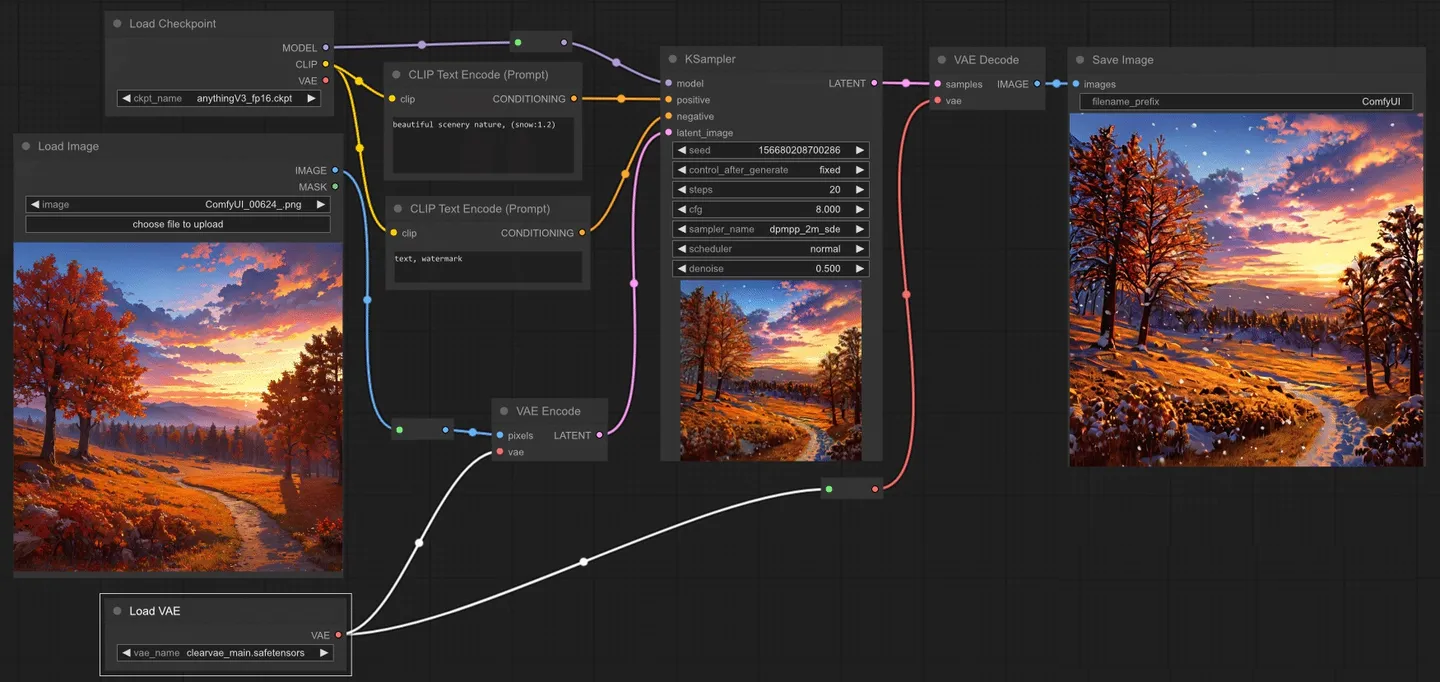
“Pad Image for Outpainting”(为外部绘画填充图像)节点
“Pad Image for Outpainting”(为外部绘画填充图像)节点可用来为外部绘画的图像添加填充,然后将此图像通过”VAE Encode for Inpainting”(为内部绘画编码的变分自动编码器)传递给修复扩散模型。[8]
输入包括图像、左侧、上方、右侧、底部以及羽化。图像是需要被填充的图像。左侧、上方、右侧以及底部分别描述了图像各边需要填充的量。羽化则用于描述原始图像边缘的柔化程度。输出包括被填充的像素图像(IMAGE)和一个用于指示采样器在何处进行外部绘画的遮罩(MASK)。
“Preview Image”(预览图像)节点
“Preview Image”(预览图像)节点可以用来在节点图内预览图像。输入是需要预览的像素图像。这个节点没有输出。
“Save Image”(保存图像)节点
“Save Image”(保存图像)节点可以用来保存图像。如果你只是想在节点图内预览图像,可以使用”Preview Image”(预览图像)节点。当你生成的图像过多,难以跟踪管理时,你可以通过一个带有文件前缀小部件的输出节点传递特殊格式的字符串来帮助组织你的图像。关于如何格式化你的字符串的更多信息,你可以查看Save File Formatting的相关内容。
输入包括需要预览的像素图像,以及一个要放入文件名中的前缀。这个节点没有输出。
图像混合(Image Blend)节点
图像混合(Image Blend)节点用于将两个图像融合在一起。
输入参数包括第一个像素图像(image1)、第二个像素图像(image2)、第二个图像的透明度(blend_factor)及图像混合方式(blend_mode)。输出则是混合后的像素图像(IMAGE)。
图像模糊(Image Blur)节点
图像模糊(Image Blur)节点可以用来对图像应用高斯模糊(Gaussian blur)。
输入(inputs)包括图片(image),这是需要被模糊化的像素图像,高斯半径(blur_radius),以及高斯的西格玛(sigma),西格玛越小,核就越集中在中心像素。输出(outputs)则是模糊化后的像素图像(IMAGE)。
图像量化(Image Quantize)节点
图像量化(Image Quantize)节点可以用来对图像进行量化处理,减少图像中的颜色数量。
输入(inputs)包括图片(image),这是需要被量化的像素图像,颜色(colors),即量化图像中的颜色数量,以及抖动(dither),即是否使用抖动技术使量化图像看起来更平滑。输出(outputs)则是量化后的像素图像(IMAGE)。
图像锐化(Image Sharpen)节点
图像锐化(Image Sharpen)节点可以用来对图像应用拉普拉斯锐化滤波器(Laplacian sharpening filter)。
输入(inputs)包括图片(image),即需要被锐化的像素图像,锐化半径(sharpen_radius),即锐化核的半径,高斯西格玛(sigma),西格玛越小,核就越集中在中心像素,以及锐化强度(alpha),即锐化核的强度。输出(outputs)则是锐化后的像素图像(IMAGE)。
使用模型放大图像(Upscale Image (using Model))节点
使用模型放大图像(Upscale Image (using Model))节点可以用来通过加载放大模型(Load Upscale Model)节点中的模型来放大像素图像。
输入(inputs)包括用于放大的模型(upscale_model)和需要被放大的像素图像(image)。输出(outputs)则是放大后的图像(IMAGE)。
潜在模型(Latent)
像稳定扩散(Stable Diffusion)这样的潜在扩散模型并不在像素空间中操作,而是在潜在空间中进行去噪处理。这些节点提供了使用编码器和解码器在像素空间和潜在空间之间切换的方法,并提供了多种操控潜在图像的方式。
空潜在图像(Empty Latent Image)节点
空潜在图像(Empty Latent Image)节点可以用来创建一组新的空白潜在图像。这些潜在图像可以被例如在text2image工作流中通过采样器节点进行噪声处理和去噪后使用。
输入(inputs)包括潜在图像的像素宽度(width)和像素高度(height),以及潜在图像的数量(batch_size)。输出(outputs)则是空白的潜在图像(LATENT)。
潜在复合(Latent Composite)节点
潜在复合(Latent Composite)节点可以用来将一个潜在图像粘贴到另一个中。
输入(inputs)包括需要被粘贴的潜在图像(samples_to),需要粘贴的潜在图像(samples_from),粘贴潜在图像的x坐标(x)和y坐标(y),以及需要粘贴的潜在图像的羽化程度(feather)。输出(outputs)则是一个包含了粘贴样本(samples_from)的新的潜在复合(LATENT)。
潜在复合遮罩(Latent Composite Masked)节点
潜在复合遮罩(Latent Composite Masked)节点可以用来将一个遮罩的潜在图像粘贴到另一个中。
信息(Info):在ComfyUI中,坐标系统的原点位于左上角。
输入(inputs)包括需要被粘贴的潜在图像(destination),需要粘贴的遮罩潜在图像(source),遮罩(mask),以及粘贴潜在图像的x坐标(x)和y坐标(y)。输出(outputs)则是一个包含了粘贴的源潜在图像(source)的新的潜在复合(LATENT)。
放大潜在图像(Upscale Latent)节点
放大潜在图像(Upscale Latent)节点可以用来调整潜在图像的大小。
警告(Warning):调整潜在图像的大小与调整像素图像的大小并不相同。直接调整潜在图像而不是像素可能会导致更多的图像失真。
输入(inputs)包括需要被放大的潜在图像(samples),用于调整大小的方法(upscale_method),目标像素宽度(Width)和目标像素高度(height),以及是否通过中心裁剪(crop)图片以保持原始潜在图像的长宽比。输出(outputs)则是调整大小后的潜在图像(LATENT)。
VAE解码(VAE Decode)节点
VAE解码(VAE Decode)节点可以用来将潜在空间图像解码回像素空间图像,解码过程使用提供的变分自编码器(VAE)。
输入(inputs)包括需要被解码的潜在图像(samples)以及用于解码潜在图像的变分自编码器(VAE)。输出(outputs)则是解码后的图像(IMAGE)。
VAE编码(VAE Encode)节点
VAE编码(VAE Encode)节点可以用来将像素空间图像编码成潜在空间图像,编码过程使用提供的变分自编码器(VAE)。
输入(inputs)包括需要被编码的像素空间图像(pixels)和用于编码像素图像的变分自编码器(VAE)。输出(outputs)则是编码后的潜在图像(LATENT)。[9]
示例(example):为了在例如图像到图像的任务中使用图像,它们首先需要被编码成潜在空间。在下面的示例中,VAE编码节点被用来将一个像素图像转换成一个潜在图像,这样我们就可以对这个图像进行重新噪声处理和去噪,从而创造出新的图像。
“Latent From Batch”节点
可以用于从一批潜在图像中提取一个切片。当需要在工作流中分离出特定的潜在图像或图像批次时,这将非常有用。
输入参数包括样本(samples,即要提取切片的一批潜在图像),批次索引(batch_index,即要提取的第一张潜在图像的索引),以及长度(length,即要取的潜在图像的数量)。输出结果是LATENT(新的只包含所选切片的潜在图像批次)。
Rebatch Latents节点
Rebatch Latents节点用于拆分或合并一批潜在图像的批次。当结果为多个批次时,该节点会输出一个批次列表,而不是单个批次。这在批次大小超过VRAM(视频随机存取内存)容量时非常有用,因为ComfyUI会按列表中的每个批次执行节点,而不是一次性执行。该节点也可用于将批次列表合并回单个批次。
输入与输出说明:输入”样本”是需要重新分批的潜在图像,”批大小”是新的批次大小。输出”LATENT”是一个潜在图像的列表,其中每个批次的大小不超过”批大小”。
Repeat Latent Batch节点
Repeat Latent Batch节点用于重复一批潜在图像。例如,这可以在图像到图像的工作流中用来创建图像的多个变体。
输入与输出说明:输入”样本”是要重复的潜在图像的批次,”数量”是重复的次数。输出”LATENT”是新的一批潜在图像,将原批次重复了设定的次数。
【Inpaint】”Set Latent Noise Mask”节点
可以用于为用于修复的潜在图像添加遮罩。设定噪声遮罩后,采样器节点只会在遮罩区域进行操作。如果提供了单一遮罩,批次中的所有潜在图像都会使用这个遮罩。
输入参数包括样本(samples,即待修复并添加遮罩的潜在图像),以及遮罩(mask,指示修复位置的遮罩)。输出结果是LATENT(经过遮罩处理的潜在图像)。
【inpaint】”VAE Encode For Inpainting”节点
“VAE Encode For Inpainting”节点可以使用所提供的变分自编码器(VAE)将像素空间的图像编码成潜在空间的图像,并接受一个用于修复的遮罩,向采样器节点指示应去噪的图像部分。通过grow_mask_by可以增加遮罩的区域,为修复过程提供一些额外的填充空间。
这个节点特别设计用于为修复训练的扩散模型,并确保编码前遮罩下的像素被设为灰色(0.5,0.5,0.5)。
输入参数包括像素(pixels,即待编码的像素空间图像),VAE(用于编码像素图像的变分自编码器),遮罩(mask,指示修复位置的遮罩),以及grow_mask_by(用于增加给定遮罩区域的量)。输出结果是LATENT(遮罩处理并编码后的潜在图像)。
“Crop Latent”节点可以用来将潜在图像裁剪到新的形状。
输入参数包括样本(samples,即待裁剪的潜在图像),宽度(width,裁剪区域的像素宽度),高度(height,裁剪区域的像素高度),以及x和y(区域的像素坐标)。输出结果是LATENT(裁剪后的潜在图像)。
“Flip Latent”节点可以用来将潜在图像进行水平翻转或垂直翻转。
输入参数包括样本(samples,即待翻转的潜在图像),以及翻转方法(flip_method,即是水平翻转还是垂直翻转)。输出结果是LATENT(翻转后的潜在图像)。
“Rotate Latent”节点可以用于将潜在图像以90度的增量顺时针旋转。
输入参数包括样本(samples,即要旋转的潜在图像),以及旋转(rotation,指定顺时针旋转的角度)。输出结果是LATENT(旋转后的潜在图像)。
Loaders,加载器
本段中的加载器可以用来加载各种工作流中使用的模型。所有加载器的完整列表可以在侧边栏中找到。
GLIGEN Loader
“GLIGEN Loader”[11]节点可以用于加载特定的GLIGEN模型。GLIGEN模型用于将空间信息关联到文本提示的部分,引导扩散模型按照GLIGEN指定的组合生成图像。
输入参数是GLIGEN模型的名称(gligen_name)。输出结果是GLIGEN模型(用于将空间信息编码到文本提示部分的模型)。
Hypernetwork Loader
Hypernetwork Loader 节点可用于加载超网络。与 LoRAs 类似,它们用于修改扩散模型,以改变潜在因素的去噪方式。典型的用例包括向模型添加生成某种风格的能力,或更好地生成某些主题或动作。甚至可以将多个超网络链接在一起以进一步修改模型。
提示:超网络强度值可以设置为负值。有时这可能会产生有趣的效果。
输入:
- model:一个扩散模型。
- hypernetwork_name:超网络的名称。
- strength:如何强烈地修改扩散模型。此值可以为负。
输出:
Load CLIP
Load CLIP 节点可用于加载特定的 CLIP 模型。CLIP 模型用于编码指导扩散过程的文本提示。
警告:条件扩散模型是使用特定的 CLIP 模型进行训练的,使用与其训练时不同的模型不太可能产生好的图像。Load Checkpoint 节点会自动加载正确的 CLIP 模型。
输入:
输出:
Load CLIP Vision
Load CLIP Vision 节点可用于加载特定的 CLIP 视觉模型。与 CLIP 模型用于编码文本提示的方式类似,CLIP 视觉模型用于编码图像。
输入:
输出:
- CLIP_VISION:用于编码图像提示的 CLIP 视觉模型。
Load Checkpoint
Load Checkpoint 节点可用于加载扩散模型,扩散模型用于去噪潜在因素。此节点还将提供适当的 VAE 和 CLIP 模型。
输入:
输出:
- MODEL:用于去噪潜在因素的模型。
- CLIP:用于编码文本提示的 CLIP 模型。
- VAE:用于将图像编码和解码到潜在空间的 VAE 模型。
Load ControlNet Model
Load ControlNet Model 节点可用于加载 ControlNet 模型。与 CLIP 模型提供一种给予文本提示以指导扩散模型的方式类似,ControlNet 模型用于为扩散模型提供视觉提示。这个过程与例如给扩散模型一个部分噪声的图像进行修改的方式不同。相反,ControlNet 模型可以用来告诉扩散模型例如最终图像中的边缘应该在哪里,或者主体应该如何摆放。此节点还可用于加载 T2IAdaptors。
输入:
- control_net_name:ControlNet 模型的名称。
输出:
- CONTROL_NET:用于为扩散模型提供视觉提示的 ControlNet 或 T2IAdaptor 模型。
Load LoRA
Load LoRA 节点可用于加载 LoRA。LoRAs 用于修改扩散和 CLIP 模型,以改变潜在因素的去噪方式。典型的用例包括向模型添加生成某种风格的能力,或更好地生成某些主题或动作。甚至可以将多个 LoRAs 链接在一起以进一步修改模型。
提示:LoRA 强度值可以设置为负值。有时这可能会产生有趣的效果。
输入:
- model:一个扩散模型。
- clip:一个 CLIP 模型。
- lora_name:LoRA 的名称。
- strength_model:如何强烈地修改扩散模型。此值可以为负。
- strength_clip:如何强烈地修改 CLIP 模型。此值可以为负。
输出:
- MODEL:修改后的扩散模型。
- CLIP:修改后的 CLIP 模型。
Load Style Model
Load Style Model 节点可用于加载风格模型。风格模型可以用于为扩散模型提供关于去噪潜在因素应该采用的风格的视觉提示。
信息:目前只支持 T2IAdaptor 风格模型。
输入:
- style_model_name:风格模型的名称。
输出:
- STYLE_MODEL:用于为扩散模型提供关于所需风格的视觉提示的风格模型。
Load Upscale Model
Load Upscale Model 节点可用于加载特定的放大模型,放大模型用于放大图像。
输入:
输出:
- UPSCALE_MODEL:用于放大图像的放大模型。
Load VAE
Load VAE 节点可用于加载特定的 VAE 模型。VAE 模型用于将图像编码和解码到潜在空间。尽管 Load Checkpoint 节点提供了一个 VAE 模型和扩散模型,但有时使用特定的 VAE 模型可能会很有用。
输入:
输出:
- VAE:用于将图像编码和解码到潜在空间的 VAE 模型。
示例: 有时您可能希望使用与随节点加载的 VAE 不同的 VAE。我们使用不同的 VAE 将图像编码到潜在空间,并解码 Ksampler 的结果。
unCLIP Checkpoint Loader
unCLIP Checkpoint Loader 节点可用于加载专为与 unCLIP 一起工作而制作的扩散模型。unCLIP 扩散模型用于去噪潜在因素,这些潜在因素不仅基于提供的文本提示,还基于提供的图像。此节点还将提供适当的 VAE、CLIP 和 CLIP 视觉模型。
警告:尽管此节点可用于加载所有扩散模型,但并非所有扩散模型都与 unCLIP 兼容。
输入:
输出:
- MODEL:用于去噪潜在因素的模型。
- CLIP:用于编码文本提示的 CLIP 模型。
- VAE:用于将图像编码和解码到潜在空间的 VAE 模型。
- CLIP_VISION:用于编码图像提示的 CLIP 视觉模型。
mask遮罩
遮罩为采样器提供了一种方法,告诉它哪些部分应该去噪,哪些部分应该保持原样。这些节点提供了各种方法来创建或加载遮罩并对其进行操作。
convert image to mask
“Convert Image to Mask” 节点可以用来将图像的特定通道转换为遮罩。
输入:
- image:要转换为遮罩的像素图像。
- channel:要用作遮罩的通道。
输出:
convert mask to image
“Convert Mask to Image” 节点可以用来将遮罩转换为灰度图像。
输入:
输出:
crop mask
“Crop Mask” 节点可以用来将遮罩裁剪成新的形状。
信息: ComfyUI 中的坐标系统原点位于左上角。
输入:
- mask:要裁剪的遮罩。
- width:区域的像素宽度。
- height:区域的像素高度。
- x:区域的 x 坐标(以像素为单位)。
- y:区域的 y 坐标(以像素为单位)。
输出:
参考:
- Comflowy - ComfyUI 社区:https://www.comflowy.com/zh-CN
- comfyUI节点介绍:https://zhuanlan.zhihu.com/p/648278481
- CLIP模型介绍(主要分Text Encoder和Image Encoder两个模块):https://zhuanlan.zhihu.com/p/666661623

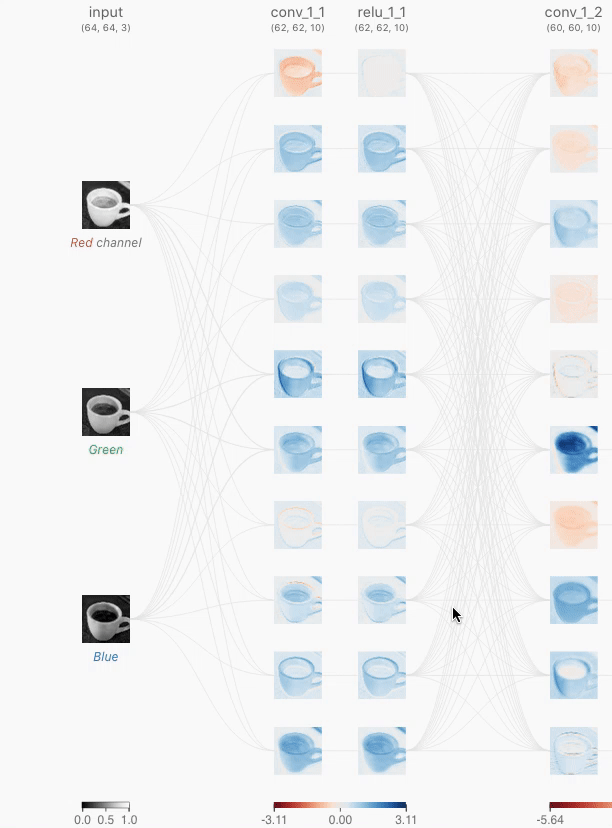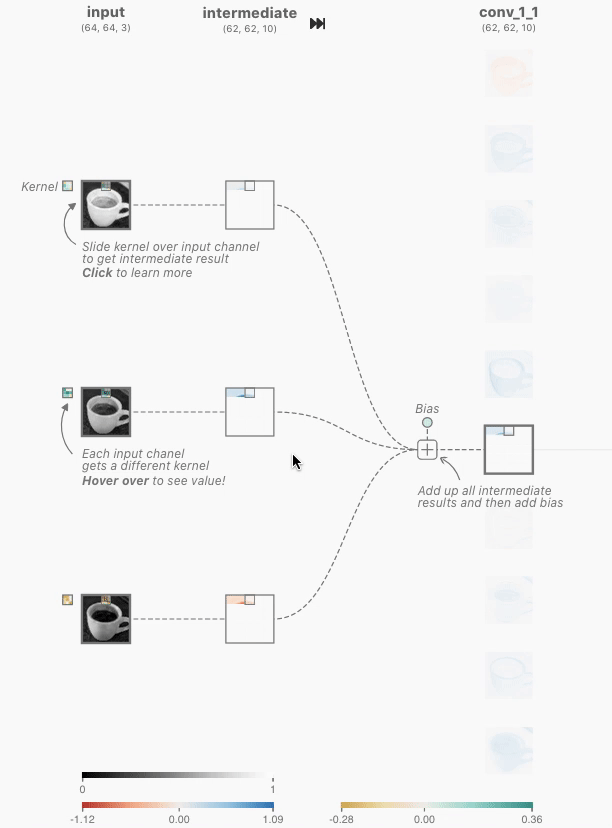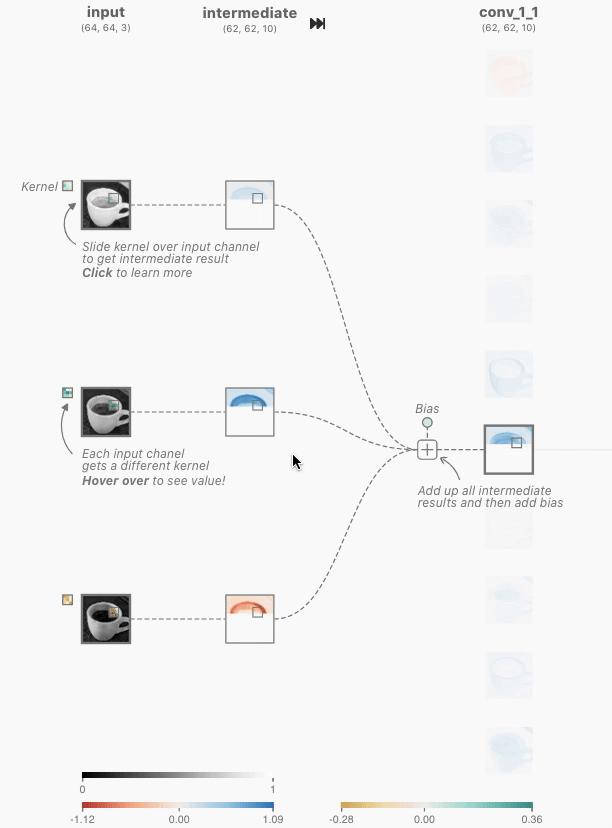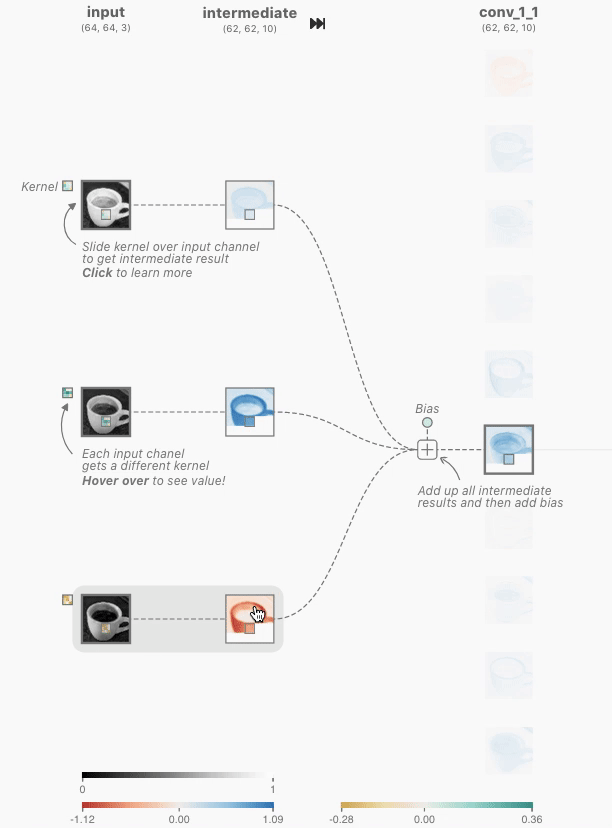
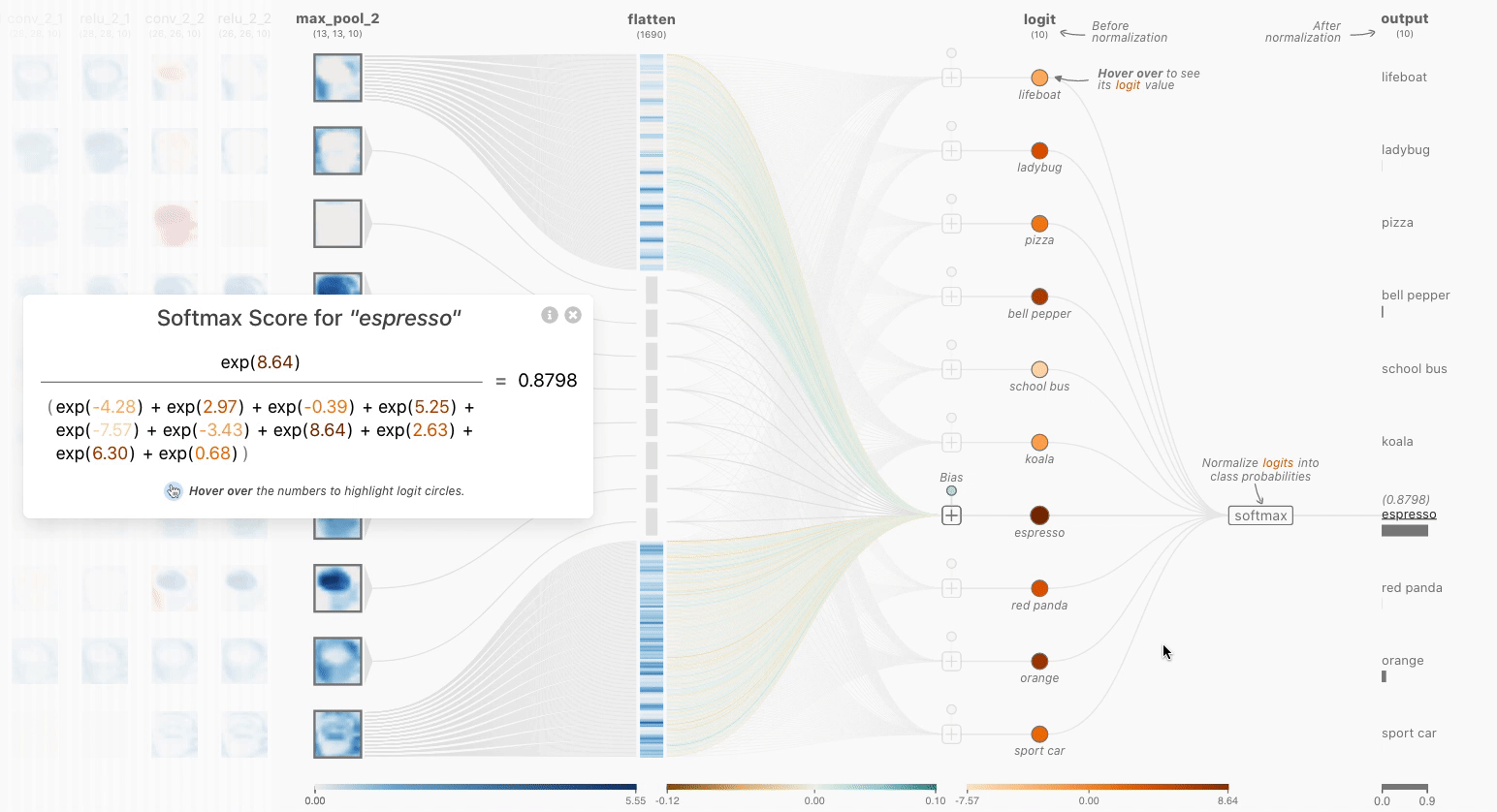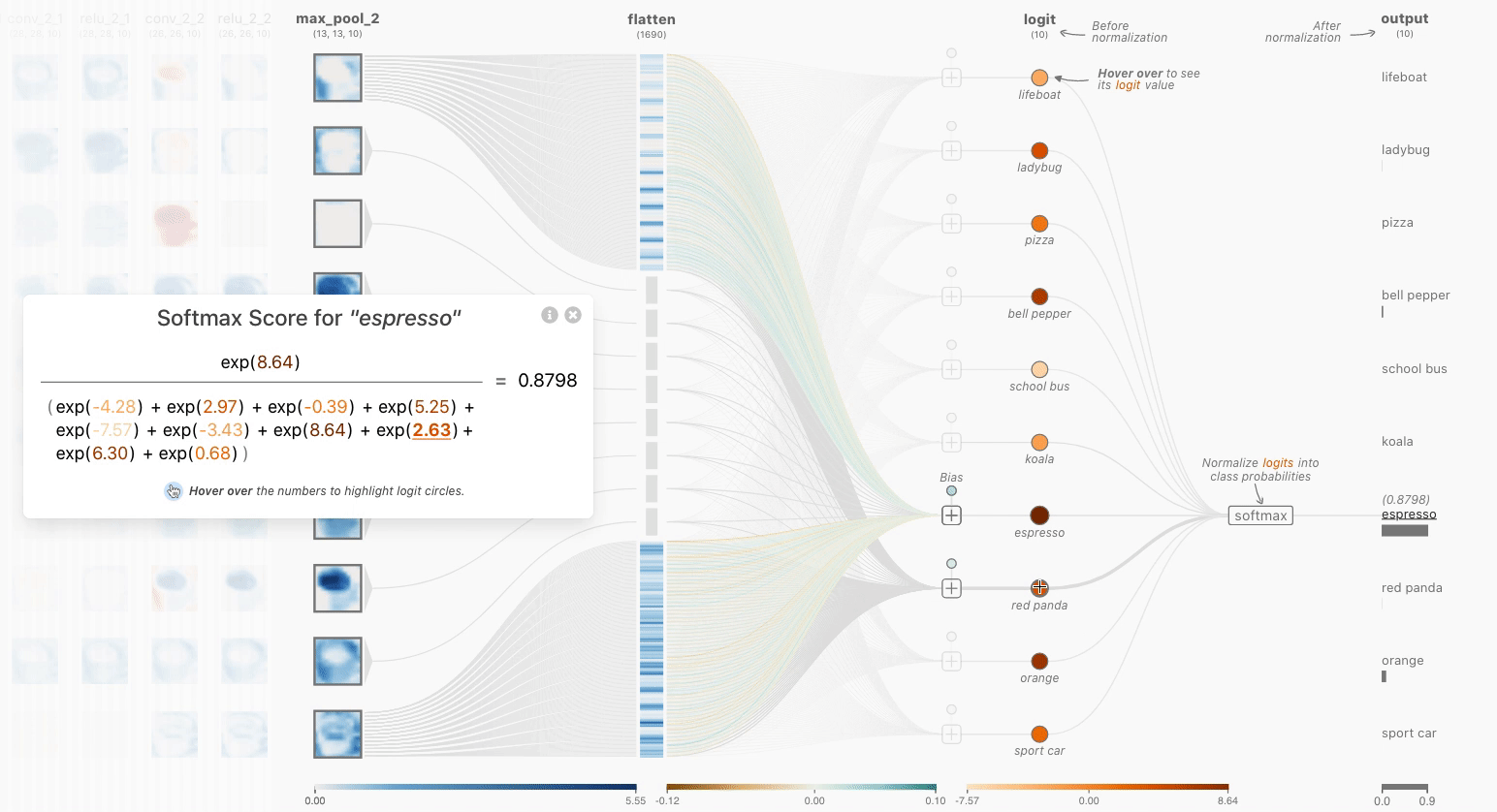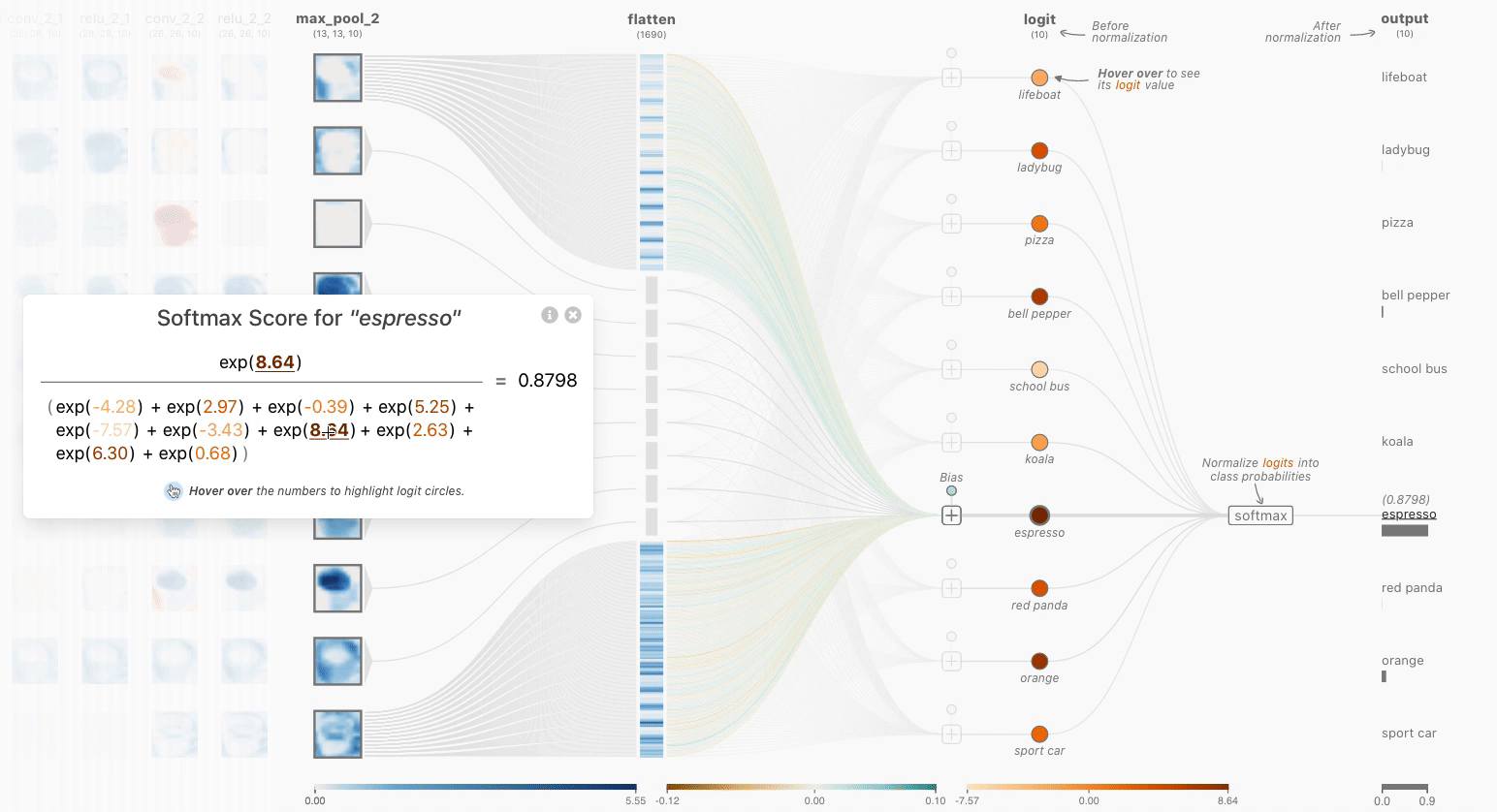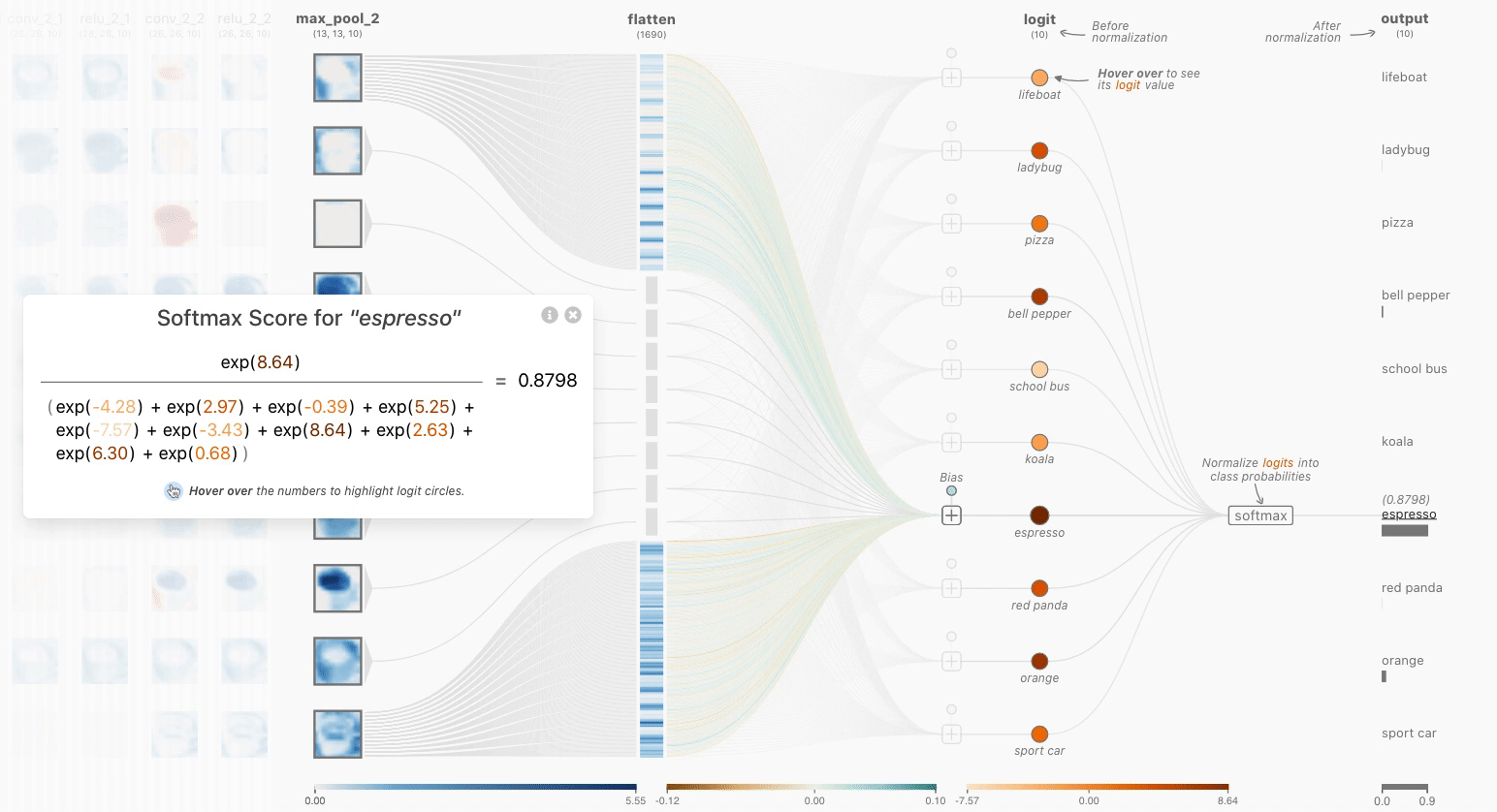
 时,使用颜色标尺显示详细信息(在这一层和其他层上)。
时,使用颜色标尺显示详细信息(在这一层和其他层上)。